Run a Recipe on a Flink Cluster on AWS EKS#
pangeo-forge-runner supports baking your recipes on Apache Flink using the Apache Flink Runner for Beam. After looking at various options, we have settled on supporting Flink on Kubernetes using Apache’s Flink Operator. This allows us to bake recipes on any Kubernetes cluster! In this tutorial, we’ll bake a recipe that we use for integration tests on an Amazon EKS k8s cluster!
Current support:
pangeo-forge-recipes version |
pangeo-forge-runner version |
flink k8s operator version |
flink version |
apache-beam version |
|---|---|---|---|---|
>=0.10.0 |
>=0.9.1 |
1.6.1 |
1.16 |
>=2.47.0 |
Setting up EKS#
You need an EKS cluster with Apache Flink Operator installed. Setting that up is out of the scope for this tutorial, but you can find some Terraform for that here.
Setting up your Local Machine as a Runner#
Install required tools on your machine.
If you don’t already have AWS Access/Secret keys you will need to create them. Then set up your credentials locally so awscli can pick them up using the configure command.
Ask your administrator to add your IAM user arn to the correct k8s
aws-authconfiguration. Then the admin will ask you to run a command to get EKS credentials locally that might look like this:$ AWS_PROFILE=<your-aws-profile> aws eks update-kubeconfig --name <cluster-name> --region <aws-cluster-region>
Verify everything is working by running the following command:
$ kubectl -n default get flinkdeployment,deploy,pod,svc
You should see the default k8s resource such as the
flink-kubernetes-operatorsimilar to what’s below:NAME READY UP-TO-DATE AVAILABLE AGE deployment.apps/flink-kubernetes-operator 1/1 1 1 15d NAME READY STATUS RESTARTS AGE pod/flink-kubernetes-operator-559fccd895-pfdwj 2/2 Running 2 (2d21h ago) 6d17h NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE service/flink-operator-webhook-service ClusterIP 10.100.231.230 <none> 443/TCP 20d service/kubernetes ClusterIP 10.100.0.1 <none> 443/TCP 20d
Setting up Runner Configuration#
Let’s first look at defining where the data that our recipes will use is stored. There are three aspects of this question we must answer:
where data is discovered/read from
where data is cached to, and
where data is output to
Where Data is Discovered#
Recipe input is defined in the recipe itself. Most recipes will define a pangeo_forge_recipes.patterns.FilePattern that provides the pipeline with input file locations.
The example below taken from this example recipe
import apache_beam as beam
import pandas as pd
from pangeo_forge_recipes.patterns import ConcatDim, FilePattern
from pangeo_forge_recipes.transforms import OpenURLWithFSSpec, OpenWithXarray, StoreToZarr
dates = [
d.to_pydatetime().strftime('%Y%m%d')
for d in pd.date_range("1996-10-01", "1999-02-01", freq="D")
]
def make_url(time):
url_base = "https://storage.googleapis.com/pforge-test-data"
return f"{url_base}/gpcp/v01r03_daily_d{time}.nc"
concat_dim = ConcatDim("time", dates, nitems_per_file=1)
pattern = FilePattern(make_url, concat_dim)
recipe = (
beam.Create(pattern.items())
| OpenURLWithFSSpec()
| OpenWithXarray(file_type=pattern.file_type, xarray_open_kwargs={"decode_coords": "all"})
| StoreToZarr(
store_name="gpcp",
combine_dims=pattern.combine_dim_keys,
)
)
Where Data is Cached#
The inputs and metadata can be cached so items don’t have to be resolved again during the next recipe run. Defining where the caching happens is part of the runner file configuration. More about that in the next session. Note that in those upcoming examples keys `InputCacheStorage`` target these options.
Where Data is Output#
Defining where the data is output is also part of the runner file configuration. More about that in the next session. Note
that in those upcoming examples the key TargetStorage defines this option.
Configuration Files#
Let’s build a configuration file for where data is cached and output. It’s recommended to configure dataset recipes using configuration files. A couple of different configuration file formats can be used as seen below.
Notice the use of {{job_name}} in the root_path configuration examples below.
{{job_name}} is special within root_path and will be treated as a template-value based on
Bake.job_name which can be provided through the CLI or in the configuration file itself and, failing
to be provided, will be generated automatically.
Also notice that we are going to store everything in s3 below because we chose s3fs.S3FileSystem. This isn’t a requirement.
Pangeo-Forge aims to be storage agnostic. By depending on fsspec we’re able to plug in supported backends.
Review other well-known fsspec built-in implementations
and fsspec third-party implementations.
JSON based configuration file:
{ "TargetStorage": { "fsspec_class": "s3fs.S3FileSystem", "fsspec_args": { "key": "<your-aws-access-key>", "secret": "<your-aws-access-secret>", "client_kwargs":{"region_name":"<your-aws-bucket-region>"} }, "root_path": "s3://<bucket-name>/<some-prefix>/{{job_name}}/output" }, "InputCacheStorage": { "fsspec_class": "s3fs.S3FileSystem", "fsspec_args": { "key": "<your-aws-access-key>", "secret": "<your-aws-access-secret>", "client_kwargs":{"region_name":"<your-aws-bucket-region>"} }, "root_path": "s3://<bucket-name>/<some-prefix>/input/cache" } }
Python based configuration file (configuration is based on the traitlets library):
BUCKET_PREFIX = "s3://<bucket-name>/<some-prefix>/" # The storage backend we want s3_fsspec = "s3fs.S3FileSystem" # Credentials for the backend s3_args = { "key": "<your-aws-access-key>", "secret": "<your-aws-access-secret>", "client_kwargs":{"region_name":"<your-aws-bucket-region>"} } # Take note: this is just python. We can reuse these values below c.TargetStorage.fsspec_class = s3_fsspec # Target output should be partitioned by `{{job_name}}` c.TargetStorage.root_path = f"{BUCKET_PREFIX}/{{job_name}}/output" c.TargetStorage.fsspec_args = s3_args c.InputCacheStorage.fsspec_class = s3_fsspec c.InputCacheStorage.fsspec_args = s3_args # Input data cache should *not* be partitioned by `{{job_name}}`, as we want to get the datafile from the source only once c.InputCacheStorage.root_path = f"{BUCKET_PREFIX}/cache/input"
Other Configuration Options#
A subset of the configuration schema that we just talked about related to inputs/outputs/caches gets dependency injected into the recipe by the runner.
Various other runner options (documented here and flink-specific here)
can also be passed either in the file configuration format above or directly during CLI bake calls. It’s recommended that you use
the file configuration because some argument values are JSON based.
Here’s a quick example of a configuration file and bake command slightly more complicated where you’re passing flink-specific configuration options and runner options.
Note that -f <path-to-your-runner-config>.<json||py> would point to the runner configuration file talked about above:
BUCKET_PREFIX = "s3://<bucket-name>/<some-prefix>/"
# The storage backend we want
s3_fsspec = "s3fs.S3FileSystem"
# Credentials for the backend
s3_args = {
"key": "<your-aws-access-key>",
"secret": "<your-aws-access-secret>",
"client_kwargs":{"region_name":"<your-aws-bucket-region>"}
}
# Take note: this is just python. We can reuse these values below
c.FlinkOperatorBakery.job_manager_resources = {"memory": "2048m", "cpu": 1.0}
c.FlinkOperatorBakery.task_manager_resources = {"memory": "2048m", "cpu": 1.0}
c.FlinkOperatorBakery.flink_configuration= {
"taskmanager.numberOfTaskSlots": "1",
"taskmanager.memory.flink.size": "1536m",
"taskmanager.memory.task.off-heap.size": "256m",
"taskmanager.memory.jvm-overhead.max": "1024m"
}
c.FlinkOperatorBakery.parallelism = 1
c.FlinkOperatorBakery.flink_version = "1.16"
# NOTE: image name must match the version of python and apache-beam being used locally
c.Bake.container_image = 'apache/beam_python3.9_sdk:2.50.0'
c.Bake.bakery_class = "pangeo_forge_runner.bakery.flink.FlinkOperatorBakery"
c.TargetStorage.fsspec_class = s3_fsspec
# Target output should be partitioned by `{{job_name}}`
c.TargetStorage.root_path = f"{BUCKET_PREFIX}/{{job_name}}/output"
c.TargetStorage.fsspec_args = s3_args
c.InputCacheStorage.fsspec_class = s3_fsspec
c.InputCacheStorage.fsspec_args = s3_args
# Input data cache should *not* be partitioned by `{{job_name}}`, as we want to get the datafile from the source only once
c.InputCacheStorage.root_path = f"{BUCKET_PREFIX}/cache/input"
pangeo-forge-runner bake \
--repo="https://github.com/pforgetest/gpcp-from-gcs-feedstock.git" \
--ref="0.10.3" \
-f <path-to-your-runner-config>.<json||py> \
--Bake.job_name=recipe \
--prune
Where you put things is your choice but please be careful: you don’t want to commit AWS secrets into GH!
Running the Recipe#
Now let’s run the integration test recipe!
Below is the minimal required configuration args for running something successful for Flink on pangeo-forge-runner>=0.9.1
where <path-to-your-runner-config>.<json||py> is your configuration file talked about above:
BUCKET_PREFIX = "s3://<bucket-name>/<some-prefix>/"
# The storage backend we want
s3_fsspec = "s3fs.S3FileSystem"
# Credentials for the backend
s3_args = {
"key": "<your-aws-access-key>",
"secret": "<your-aws-access-secret>",
"client_kwargs":{"region_name":"<your-aws-bucket-region>"}
}
# Take note: this is just python. We can reuse these values below
c.FlinkOperatorBakery.flink_configuration= {
"taskmanager.numberOfTaskSlots": "1",
}
c.FlinkOperatorBakery.parallelism = 1
c.FlinkOperatorBakery.flink_version = "1.16"
# NOTE: image name must match the version of python and apache-beam being used locally
c.Bake.container_image = 'apache/beam_python3.9_sdk:2.50.0'
c.Bake.bakery_class = "pangeo_forge_runner.bakery.flink.FlinkOperatorBakery"
c.TargetStorage.fsspec_class = s3_fsspec
# Target output should be partitioned by `{{job_name}}`
c.TargetStorage.root_path = f"{BUCKET_PREFIX}/{{job_name}}/output"
c.TargetStorage.fsspec_args = s3_args
c.InputCacheStorage.fsspec_class = s3_fsspec
c.InputCacheStorage.fsspec_args = s3_args
# Input data cache should *not* be partitioned by `{{job_name}}`, as we want to get the datafile from the source only once
c.InputCacheStorage.root_path = f"{BUCKET_PREFIX}/cache/input"
pangeo-forge-runner bake \
--repo=https://github.com/pforgetest/gpcp-from-gcs-feedstock.git \
--ref="0.10.3" \
-f <path-to-your-runner-config>.<json||py> \
--Bake.job_name=recipe \
--prune
Note that Bake.prune=True onlys tests the recipe by running the first two time steps like the integration tests do.
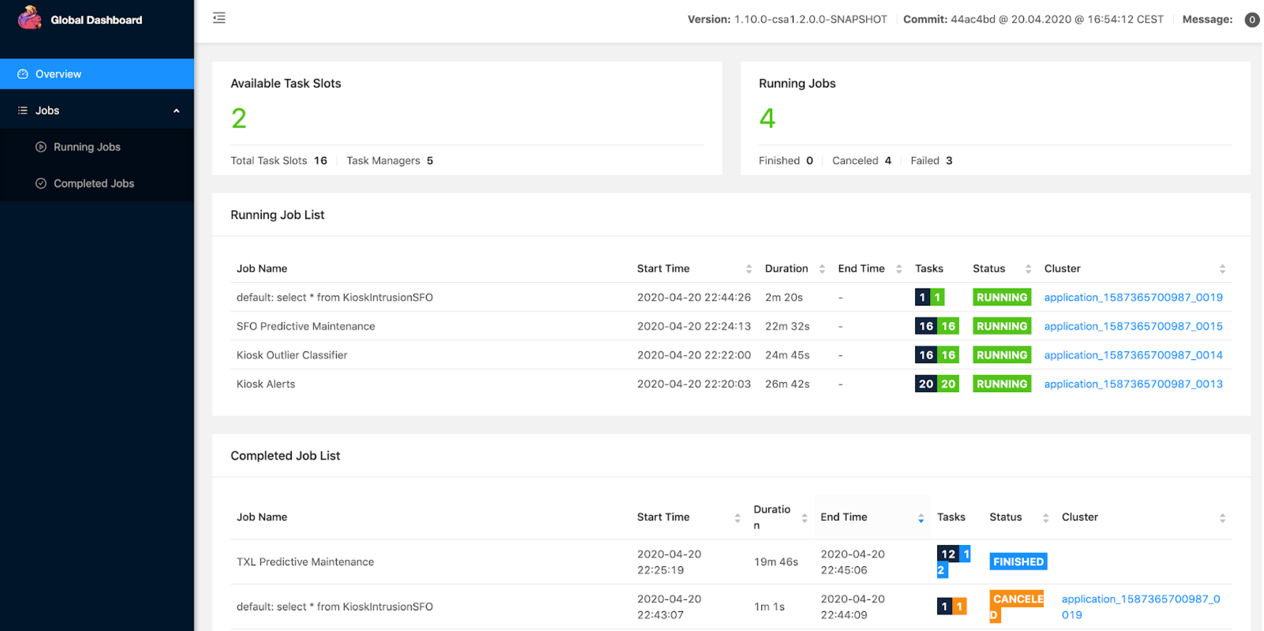
Monitoring Job Output via the Flink Dashboard#
After you run the pangeo-forge-runner command, among the many lines of output,
you should see something that looks like:
You can run 'kubectl port-forward --pod-running-timeout=2m0s --address 127.0.0.1 <some-name> 0:8081' to make the Flink Dashboard available!
If you copy the command provided in the message and run it, it should provide you with a local address where the Flink Job Manager Dashboard will be available!
$ kubectl port-forward --pod-running-timeout=2m0s --address 127.0.0.1 <some-name> 0:8081
Forwarding from 127.0.0.1:<some-number> -> 8081
Copy the 127.0.0.1:<some-number> URL to your browser, and tada! Now you can watch our job and tasks remotely
Monitoring Job Output via k8s Logs#
There are other ways to understand when your jobs/tasks have completed by querying the k8s logs. The job manager will include any tracebacks from your task managers and will also include the most reasonable output about whether things succeeded
First, list out your pods and find your job manager pod as noted below:
$ kubectl -n default get pod
Then grok the output and pay attention to these notes:
NAME READY STATUS RESTARTS AGE
pod/flink-kubernetes-operator-559fccd895-pfdwj 2/2 Running 2 (3d1h ago) 6d21h
# NOTE: the job manager here gets provisioned as `<Bake.job_name>-<k8s-resource-hash>`
# so `Bake.job_name="nz-5ftesting"` in this case
pod/nz-5ftesting-66d8644f49-wnndr 1/1 Running 0 55m
# NOTE: the task managers always have a similar suffix depending on your
# `--FlinkOperatorBakery.parallelism` setting. Here it was set to `--FlinkOperatorBakery.parallelism=2`
pod/nz-5ftesting-task-manager-1-1 1/1 Running 0 55m
pod/nz-5ftesting-task-manager-1-2 1/1 Running 0 55m
Dumping the job manager logs and grepping for this line will signal a success or failure of overall job:
$ kubectl -n default logs pod/nz-5ftesting-66d8644f49-wnndr | grep 'Job BeamApp-flink-.*RUNNING to.*'
# which might show this in a fail case:
2023-11-06 17:46:20,299 INFO org.apache.flink.runtime.executiongraph.ExecutionGraph
[] - Job BeamApp-flink-1106174115-5000126 (d4a75ed1adf735f89649113c82b4f45a) switched from state RUNNING to FAILING.
# or this in a successful case
2023-11-06 17:46:20,299 INFO org.apache.flink.runtime.executiongraph.ExecutionGraph
[] - Job BeamApp-flink-1106174115-5000126 (d4a75ed1adf735f89649113c82b4f45a) switched from state RUNNING to COMPLETED.
Flink Memory Allocation Tricks and Trapdoors#
Sometimes you’ll have jobs fail on Flink with errors about not enough off-heap memory or the JVM being OOM killed. Here
are some configuration options to think about when running jobs.
The kind: FlinkDeployment resource has a goal which is to spin up a job manager. The job manager has a goal which is
to spin up the task managers (depending on your --FlinkOperatorBakery.parallelism setting). In k8s land
you can get a sense for which deployment/pod is which by considering your --Bake.job_name:
First run this command:
$ kubectl -n default get pod
Then consider this output:
NAME READY STATUS RESTARTS AGE
pod/flink-kubernetes-operator-559fccd895-pfdwj 2/2 Running 2 (3d1h ago) 6d21h
# NOTE: the job manager here gets provisioned as `<Bake.job_name>-<k8s-resource-hash>`
pod/nz-5ftesting-66d8644f49-wnndr 1/1 Running 0 55m
# NOTE: the task managers always have a similar suffix depending on your
# `--FlinkOperatorBakery.parallelism` setting. Here it was set to `--FlinkOperatorBakery.parallelism=2`
pod/nz-5ftesting-task-manager-1-1 1/1 Running 0 55m
pod/nz-5ftesting-task-manager-1-2 1/1 Running 0 55m
If we grok the first ten lines of the job manager logs we get a nice ascii breakdown of the job manager resourcing that corresponds to the matching Flink memory configurations.
Run this command:
$ kubectl logs pod/nz-5ftesting-66d8644f49-wnndr | grep -a6 "Final Master Memory configuration:"
Consider this output:
INFO [] - Loading configuration property: jobmanager.memory.process.size, 6144m
INFO [] - Loading configuration property: taskmanager.rpc.port, 6122
INFO [] - Loading configuration property: internal.cluster.execution-mode, NORMAL
INFO [] - Loading configuration property: kubernetes.jobmanager.cpu, 1.0
INFO [] - Loading configuration property: prometheus.io/scrape, true
INFO [] - Loading configuration property: $internal.flink.version, v1_16
INFO [] - Final Master Memory configuration:
# set via: `--FlinkOperatorBakery.job_manager_resources='{"memory": "<size>m", "cpu": <float>}'`
# corresponds to: https://nightlies.apache.org/flink/flink-docs-release-1.16/docs/deployment/config/#jobmanager.memory.process.size
INFO [] - Total Process Memory: 6.000gb (6442450944 bytes)
# set via: `-FlinkOperatorBakery.flink_configuration='{"taskmanager.memory.flink.size": "<size>m"}'`
# corresponds to: https://nightlies.apache.org/flink/flink-docs-release-1.16/docs/deployment/config/#jobmanager-memory-flink-size
INFO [] - Total Flink Memory: 5.150gb (5529770384 bytes)
INFO [] - JVM Heap: 5.025gb (5395552656 bytes)
INFO [] - Off-heap: 128.000mb (134217728 bytes)
INFO [] - JVM Metaspace: 256.000mb (268435456 bytes)
INFO [] - JVM Overhead: 614.400mb (644245104 bytes)
While the task manager doesn’t have this nice memory configuration breakdown, the Flink memory configurations have all the same options for the task managers.
These settings are probably recipe specific b/c it depends what you are doing. A good default is to set the job/task manager process memory higher than needed and hope that the fractional allocations talked in the Flink memory configuration will carve off enough room to do their job.
Then only adjust if you are getting specific errors about memory. The one caveat here is that taskmanager.memory.flink.size
can’t have a fractional allocation of total process memory and so it’s best to set it outright at or below your total process memory:
pangeo-forge-runner bake \
--repo=https://github.com/pforgetest/gpcp-from-gcs-feedstock.git \
--ref="0.10.3" \
-f <path-to-your-runner-config>.<json||py> \
# corresponds to: https://nightlies.apache.org/flink/flink-docs-release-1.16/docs/deployment/config/#jobmanager.memory.process.size
--FlinkOperatorBakery.job_manager_resources='{"memory": "2048m", "cpu": 0.3}' \
# corresponds to: https://nightlies.apache.org/flink/flink-docs-release-1.16/docs/deployment/config/#taskmemory.memory.process.size
--FlinkOperatorBakery.task_manager_resources='{"memory": "2048m", "cpu": 0.3}' \
# corresponds to any options from: https://nightlies.apache.org/flink/flink-docs-release-1.16/docs/deployment/config/
--FlinkOperatorBakery.flink_configuration='{"taskmanager.numberOfTaskSlots": "1", "taskmanager.memory.flink.size": "1536m"}' \
# corresponds to: https://nightlies.apache.org/flink/flink-docs-release-1.16/docs/deployment/config/#pipeline-max-parallelism
--FlinkOperatorBakery.parallelism=1 \
--FlinkOperatorBakery.flink_version="1.16" \
--Bake.prune=True \
--Bake.job_name=recipe \
# corresponds: https://nightlies.apache.org/flink/flink-docs-release-1.16/docs/deployment/config/#kubernetes-container-image
--Bake.container_image='apache/beam_python3.9_sdk:2.50.0' \
--Bake.bakery_class="pangeo_forge_runner.bakery.flink.FlinkOperatorBakery"